Google, the EU and history.
But Google’s not alone. Under the EU ruling, Facebook, Twitter, and YouTube would all be considered search engines and would all have to remove links to content if someone like Mr. Sterling (or his considerable legal team) were to approach them and say that he believed the information was irrelevant or hurtful to his reputation so that Google, Facebook, Twitter and YouTube would all have to remove it.
Google's system of organizing and ranking information that it doesn't control also poses considerable challenges.
The Burden of managing different masters
We also need to ask how all of these guys manage the needs of the EU with those of the US and other nations? If the Spaniard requests that info be taken down, does it disappear off of Google searches from the US as well?
With this recent EU ruling flying in the face of Google's stated mission to "organize the world's information and make it universally accessible and useful," and this recent ruling flying in the face of that, there's no doubt that Google's global legal team is burning the midnight oil to up with an effective defense. After all, a little thing like this isn't going to keep Google from continuing to use the power of transparent data to change the world.
Note: A version of this article appeared on The Drill Down website on May 14th, 2014. The Podcast covered the topic in detail during episode 326
Today the Court of Justice of the European Union ruled that if someone searches your name, and the results that show up list information that you don’t care to be remembered, you can request that the search engine company posting those results, remove those links or otherwise remove the data.
The Ruling that could change the face of the Web
The Court ruled this way using the principle of “right to be forgotten.” RTBF, as we’ll call it, means that when it comes to search engine results about individual people (in this case, EU citizens), those people now have the ability to request that certain bits of information about their lives be removed since they believe those results are no longer relevant.
How did we get here?
The BBC has an in-depth recount but here's the gist: Sixteen years ago a Spaniard fell into some debt. In order to get out from under the burden, an auction was put on for one of his properties. A local newspaper wrote a story about the affair and, in the course of the last decade-and-a-half, all of that publication’s information ended up on the Web. When you search for the Spaniard’s name, information about the sale of his property to pay his debts appears prominently on Google’s results page.
The BBC has an in-depth recount but here's the gist: Sixteen years ago a Spaniard fell into some debt. In order to get out from under the burden, an auction was put on for one of his properties. A local newspaper wrote a story about the affair and, in the course of the last decade-and-a-half, all of that publication’s information ended up on the Web. When you search for the Spaniard’s name, information about the sale of his property to pay his debts appears prominently on Google’s results page.
The Spaniard is not happy about this. He took Google to court in the EU stating that these facts from sixteen years ago were getting in the way of his reputation, which in turn, affected his ability to do business. The high court agreed by saying:
So far as concerns, next, the extent of the responsibility of the operator of the search engine, the Court holds that the operator is, in certain circumstances, obliged to remove links to web pages that are published by third parties and contain information relating to a person from the list of results displayed following a search made on the basis of that person’s name. The Court makes it clear that such an obligation may also exist in a case where that name or information is not erased beforehand or simultaneously from those web pages, and even, as the case may be, when its publication in itself on those pages is lawful.
Even if the web page that holds the information that the person doesn't want made available to the world has put that information up legally, the person in question can effectively stop any other person from finding the information by removing it from a search engine.
The Problem with removing Search Engine Results
The Internet, and the World Wide Web you’re using to read this post, is almost incomprehensible without the utility of a search engine. Articles, pages and documents strafe across the Internet like stars across the night sky and without a search engine as your sexton, there’s very little chance anyone can navigate it effectively.
The implications are vast. In the last few weeks search engines like Google have been accessed by millions of people to understand the controversy surrounding the Los Angeles Clippers and Donald Sterling. The team’s never won a championship but, now based on the controversy, The LA Clippers are trending higher than any other basketball team currently searched for on Google. It moved up 17 spots in the last month.
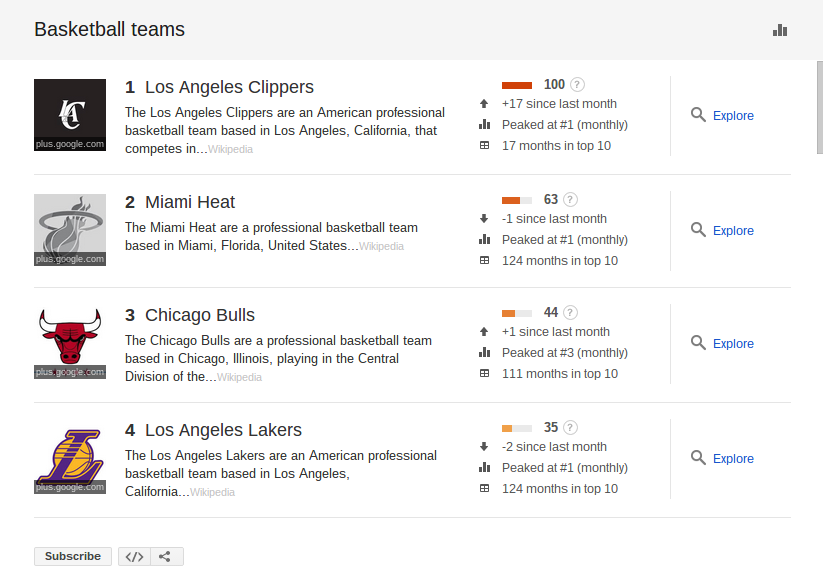 |
| Take a quick look at the info beside each team. Three of these four have been top ten searched terms for over 100 months. The Clippers, the number one searched team, has been in the top ten for a lot less time. |
- If your friend told you to search for Sterling’s quotes on Google the information wouldn’t be there
- If your friend sent you a link via Twitter or Facebook, those sites would have to remove the link.
- If your friend had a video of someone like Sterling or Cliven Bundy on YouTube, the video service would have to remove any search links, they’d also have to remove the actual video.
Since Sterling has long owned the LA Clippers, the EU might find that he falls into what they referred to as a Public Figure, so perhaps this data would remain. But Cliven Bundy wasn’t a public figure until very recently, which means that he may have requested that YouTube take down this video and others like it on grounds that he found it irrelevant. And if they hadn't he could have sued because the following video could have hurt his reputation.
Any way you slice it, recent scandals, controversies and revelations may have all been hidden from public view if these characters had this new protection in place and argued that they were indeed private citizens.
Complying with these laws drives up costs for online businesses
Building the tools to comply with these new requirements isn't impossible, but it's certainly going to put a substantial drag on the resources of both up and coming and established tech companies. Facebook and YouTube allow users to delete posts, and they also have reasonably robust mechanisms for complaining about other people's posts whether they be offensive or infringe upon an existing copyright. Google's system of organizing and ranking information that it doesn't control also poses considerable challenges.
- How do they verify that the request is coming from the actual person involved?
- How do they determine if that person is a private citizen or in public life?
- How do they determine whether or not the data their linking to is irrelevant?
The Burden of managing different masters
We also need to ask how all of these guys manage the needs of the EU with those of the US and other nations? If the Spaniard requests that info be taken down, does it disappear off of Google searches from the US as well?
Twitter's in a particularly interesting situation. Like Facebook and YouTube, Twitter's a content network. Twitter's secondary role is that of a real-time search engine. The user-generated content on Twitter moves so fast and is so robust that the United States Library of Congress, as part of their chartered mission to capture "America's Story," started downloading Twitter's tweets in April of 2010 and has no intention of letting that history be destroyed.
By telling search engines and other online services to remove search results upon request, the Eu is opening the door to allowing vast amounts of data-- of history no less, to fall into obscurity; swallowed up and forever lost like the tomes of another library -- the one at Alexandria.
Similar Laws are about to go live in the US
It may be that Google and others work to adopt one standard across the world. After all, last Fall (2013) California passed an RTBF law stating that its minor population had the right request that any website they posted to had to pull down any posted content at their request. The law is designed to help youngsters get past any troubling images or opinions they may have posted whilst still in the grasp of teen angst. The unintended consequences however, begin to mirror the intentions of the recent EU ruling. With this recent EU ruling flying in the face of Google's stated mission to "organize the world's information and make it universally accessible and useful," and this recent ruling flying in the face of that, there's no doubt that Google's global legal team is burning the midnight oil to up with an effective defense. After all, a little thing like this isn't going to keep Google from continuing to use the power of transparent data to change the world.
No comments:
Post a Comment